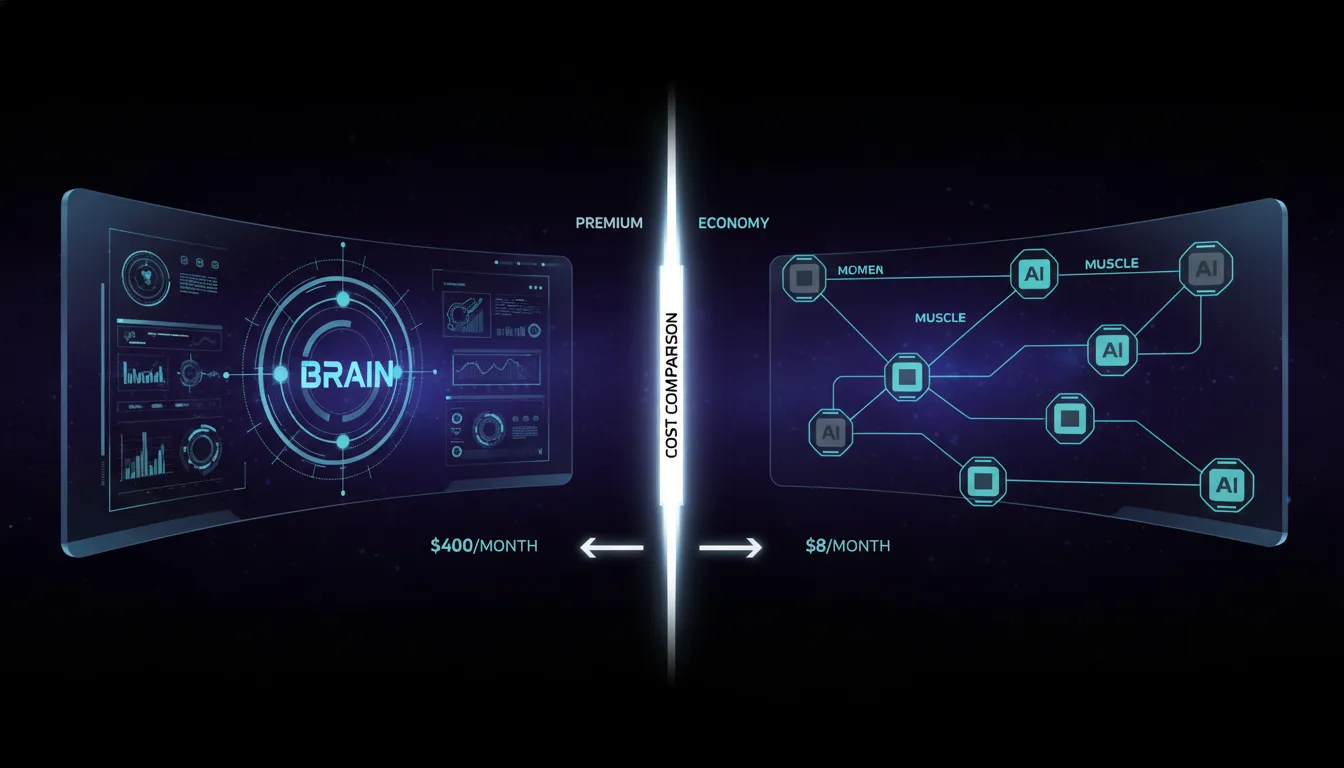
Two people open the same AI agent framework, connect it to the same tasks, and run it around the clock for a month. One receives a $400 bill. The other pays $8. Neither considers their result unusual. Both are correct.
This is the defining split in autonomous AI right now, and it has nothing to do with which model is best. It has everything to do with which model each task actually needs. The discipline of routing inference requests to the cheapest capable model, often called model routing or model tiering, is turning what once seemed like a luxury AI workflow into something closer to a basic utility expense. The people who understand this are operating at a 30x to 50x cost advantage over those who do not.
Moe Lueker, the developer behind Hermes Agent, put the math plainly: "I'm running Hermes Agent 24/7 and my total API cost last month was just eight bucks. With the setup that I'm about to show you, you do not need a $100 a month Claude subscription." That claim would have sounded implausible eighteen months ago. In mid-2026, with the current generation of cheap reasoning models and aggressive caching discounts, it is reproducible.
The $400 Assumption
Most people who build their first agentic AI workflow make the same mistake: they pick the frontier model they trust most, usually Claude Opus or GPT-5.5, and route every single operation through it. The logic is understandable. Those models are the most capable. For a personal assistant handling scheduling, email, coding, note compression, and web research simultaneously, it feels safer to have maximum intelligence at every step.
The cost reality is brutal. As Lueker noted, "You might say, 'Oh man, I'm going to spend like $300 to $400 a month on Opus API. That's a lot of money.'" That figure is not hypothetical. Some users pushed further: community reports documented individuals spending close to $5,000 on API costs at an average of $131 per day using Claude Opus for heavy agentic work. At that scale, the AI is not a productivity tool. It is a recurring operating expense that rivals a junior employee's salary.
The core inefficiency is a mismatch between task complexity and model capability. An Opus-class model summarizing yesterday's emails is like hiring a neurosurgeon to take your blood pressure. The capability is there. The price is not justified by what is being asked. As Lueker framed it, "This can really make or break your budget because if you choose this wrong, you might be paying 30 times as much for something that doesn't need as much brain power."
The Routing Architecture
The solution that has emerged in the agentic AI community is a tiered model architecture, sometimes called the Brain Muscle Model. The structure is simple: one expensive frontier model acts as the orchestrator, the "brain," making high-level judgments and handling tasks where reasoning quality is genuinely decisive. A layer of cheaper, faster models acts as "muscles," executing specific sub-tasks that do not require frontier-level reasoning. A third background layer handles repetitive compression, summarization, and classification work at bulk discount prices.
Hermes implements this as a Primary/Auxiliary/Fallback three-tier system. The primary model handles the main conversational and reasoning loop. The auxiliary model runs in the background for compression, summarization, and context management. The fallback model activates when the primary hits rate limits. Lueker's framing is unambiguous: "The primary model is what you communicate with. The auxiliary model is something Hermes uses in the background for compression, summarization, and this should ideally be something cheaper. Using the same model for everything just burns your tokens."
The cost differential between these tiers is not marginal. DeepSeek, at approximately 27 cents per million tokens, costs about one-tenth of what Claude Opus 4.6 charges before cache hits. Cache hits on repeated context, common in long-running agent sessions that reference the same system prompts and tool definitions repeatedly, drop the effective price another 120 times. For background summarization tasks that run dozens of times per day, the compounded discount makes the cost effectively negligible.
Benchmark comparisons illustrate the range. A full three-task coding benchmark run on Grok 4.3 costs 13 cents. The same multi-turn task on GPT-5.5 runs $165. These are not interchangeable options for all purposes, but for tasks where Grok 4.3's capability is sufficient, the cost argument is overwhelming.
The Routing Map in Practice
"The old argument was which model is best. The better argument is which model should handle this step. Use a local Gemma class model for cheap background classification. Use GPT 5.5 for hard implementation. Use Claude API when the judgment or architectural reasoning is worth the metered cost. Use cheaper hosted models for bulk summarization." Model routing framework, Aether Intel synthesis from developer community
This philosophy produces a specific mental model for task assignment. Writing emails goes to a mid-tier capable model with strong prose quality, such as GPT-5.5. Water reminders and low-stakes notifications route to local Llama or a similarly inexpensive model. Complex coding problems and architectural decisions route to Opus. The routing decision is not about the best possible answer. It is about the minimum sufficient answer for each task type.
One creator whose "brain and muscle model" video accumulated 95,000 views described the architecture directly: "Having an orchestrator model and then muscles with cheap models on each... the brain and muscle model." The framework resonated because it reframes cost optimization not as cutting corners but as appropriate resource allocation. You are not using a worse model. You are using the correct model for the job.
The task-type routing reflex, once developed, operates as a quick classification step before any inference call. What is the intelligence requirement here? What is the failure cost if the output is mediocre? What context does this task share with previous calls, making cache hits likely? Those three questions, answered quickly, produce a routing decision that can reduce monthly costs by 90 percent or more while maintaining output quality where it actually matters.
The Cost Comparison
| Setup Type | Monthly Cost | Routing Flexibility | 24/7 Capable | Self-Improving |
|---|---|---|---|---|
| Routed multi-tier (e.g., Hermes optimized) | $8 | High: Brain/Muscle/Background split | Yes | Yes |
| Single frontier model, moderate use | $300-400 | Low: All traffic to one endpoint | Yes | Limited |
| Flat-rate subscription (e.g., $100/mo Claude) | $100 | None: Fixed model, rate-limited | No | No |
| Heavy agentic, frontier only, no optimization | $1,000-5,000 | None: Unmanaged API spend | Technically | No |
The Counterintuitive Warning
There is a tension at the center of this discussion that the cost-optimization community has largely resolved but rarely explains clearly. The same creators who teach the $8/month setup also issue a firm warning that sounds like a contradiction.
The resolution is in the distinction between the main agent brain and the sub-task muscles. The warning applies specifically to the orchestrator, the primary model responsible for understanding intent, managing context across sessions, making routing decisions, and producing outputs the user directly interacts with. Cutting costs at the orchestrator level produces visible degradation: missed instructions, broken reasoning chains, hallucinated tool calls. That is where the $8/month practitioner still uses Opus. The cheap models handle everything downstream of that decision.
The 92 percent cost reduction comes from routing routine sub-tasks, not from replacing the reasoning core. DeepSeek at 27 cents per million tokens handles compression runs that happen automatically in the background dozens of times per day. The user never sees those outputs directly. The quality bar is "good enough to maintain context coherence," not "indistinguishable from frontier reasoning." That distinction is what makes the economics work.
The Routing Reflex as Durable Skill
Model prices are volatile. What costs 27 cents per million tokens today may cost 3 cents or 2 dollars in eighteen months. The specific numbers in any routing configuration will need updating. The underlying skill, the reflex of classifying tasks by intelligence requirement before assigning them to a model tier, is model-agnostic and durable.
Writing emails: a capable mid-tier model with good prose. Water reminders: the cheapest local model that can parse a time and send a ping. Coding: the best available reasoning model. Bulk summarization: whatever offers the lowest per-token cost with adequate coherence. This thinking system transfers to any combination of models the market produces next year or the year after.
The gap between the $8 operator and the $400 operator is not primarily a gap in technical sophistication. It is a gap in how each person thinks about inference costs before a single API call is made. One treats every task as equivalent. The other treats routing as the first and most important decision. The models themselves are secondary to that distinction, and that distinction, once internalized, does not expire when the next generation of frontier models arrives.