RESEARCH DESK
Research
Benchmarks, model comparisons, and capability studies — built for people who need to make real decisions about AI tools.
Featured Research
Our most thorough comparative analyses and benchmarks.

Model Benchmarks
How today's most-used models stack up on tasks that matter to builders.
| Model | Provider | Reasoning | Coding | Long Context | Cost/1M tokens |
|---|---|---|---|---|---|
| GPT-4o | OpenAI | 92 | 88 | 85 | $5.00 / $15.00 |
| Claude 3.5 Sonnet | Anthropic | 91 | 94 | 96 | $3.00 / $15.00 |
| Llama 3.1 70B | Meta (Open) | 83 | 79 | 80 | $0.29 / $0.59 |
| Gemini 1.5 Pro | 88 | 82 | 99 | $3.50 / $10.50 | |
| Mixtral 8x7B | Mistral (Open) | 71 | 74 | 68 | $0.27 / $0.27 |
Scores are composite estimates from public benchmarks and our internal testing. Cost = input / output per 1M tokens. Updated May 2026.
Research Articles
Structured analyses and cost/capability studies.
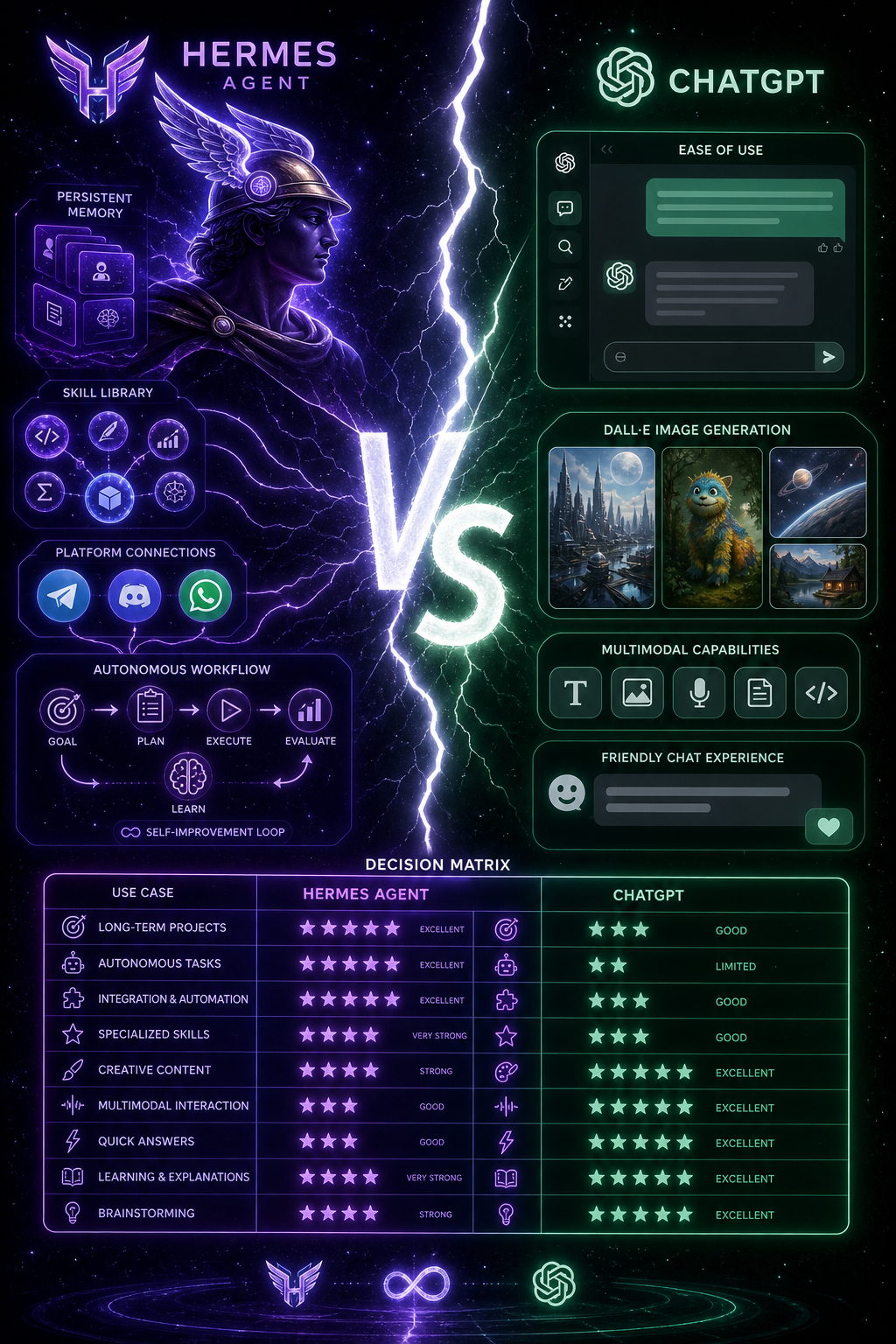
Comparison
Hermes vs ChatGPT: Which Wins for Builders?
Head-to-head on 8 real-world builder tasks with concrete scores.

Cost Analysis
Hermes Cost Guide: Run AI Cheaply at Scale
From $50/mo down to under $8 — the right routing strategy matters.

API Guide
OpenRouter: Access 100+ AI Models With One Key
Setup, routing, and cost optimization for multi-model workflows.